
When training a model based on machine-learning (ML) or deep-learning (DL), data augmentation (DA) is a crucial technique to improve the model’s generalization performance and train better representation. However, it relies heavily on human experience or intuition. The ML/DL community has recognized this problem and has been making efforts to find ways to effectively perform data augmentation automatically. In this article, we will discuss automatic augmentation policy searching, an exploration-based approach, as one of the research efforts to reduce the dependence on humans and perform data augmentation more effectively.
Generalization in Deep Learning
Deep neural network (DNN) is an extremely flexible universal function approximator. Therefore, when training a DNN model on a given dataset, it often leads to overfitting. When overfitting occurs, the model will not perform well on datasets it was not trained on, no matter how good its training dataset was. This is often referred to as having “poor generalization performance.”
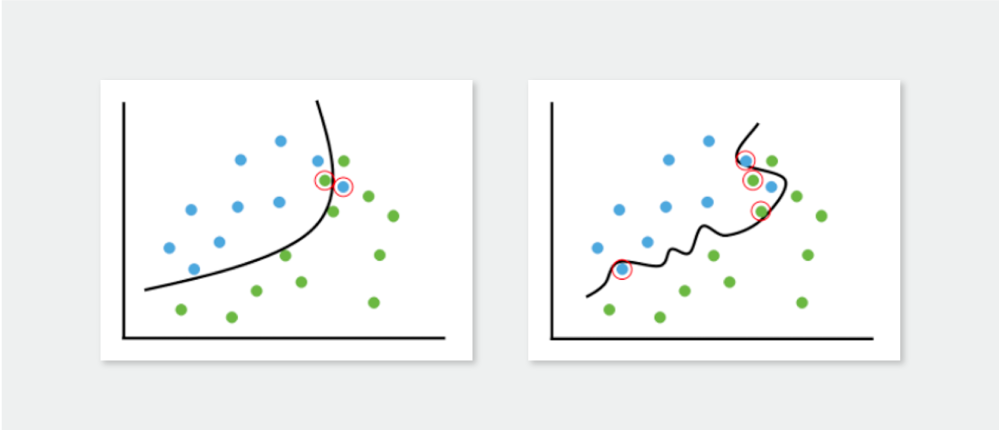
The fundamental reason behind overfitting is that the capacity of a DNN model is generally much larger than the provided training dataset. In this case, the DNN simply “memorizes” the training data. Because the training dataset is small, it doesn’t bother to learn the inherent features. This is why the model struggles to solve a problem correctly when it encounters data that is even slightly different. Therefore, generalization is crucial for the practical use of DL-based models. Extensive research has been conducted to address this issue, and a basic yet effective method to use is data augmentation.
Applying Data Augmentation to Deep Learning
Overfitting does not occur if data is continuously provided. However, in practice, it’s not possible to constantly provide data. Data augmentation is an approach that inflates the given data and uses it for training, instead of getting an infinite amount of data. As shown in [Figure 2], a single image of a koala can be generated into numerous similar images. When a DNN is trained to classify all these augmented koala images, it finds and learns common characteristics from them. This allows the DNN to learn the features inherent in the dataset and avoid overfitting, rather than simply memorizing the data.

So, does blindly applying data augmentation to train a model always prevent overfitting? Of course not – too much data augmentation can destroy the original characteristics of the data and confuse the model instead. Then what is the appropriate augmentation for a specific task? It would be impossible to define precisely. Data augmentation is an important and basic technique that is almost always used, but in practice, we have to rely on human intuition and experience to choose the “appropriate” augmenting operation.
Automatic Data Augmentation
The problem of finding the range of “appropriate” augmentation is precisely what automatic data augmentation aims to address. Related research can be categorized into four main areas. Of these, I’d like to introduce two of the categories that fall under augmentation.
Data augmentation
Single operation
- Manually designed single operation: Designed with an engineer’s intuition and experience.
- Automatically designed single operation: With an augmentation network, an engineer only needs to define the loss function and the network will learn augmentation by itself.
Combination of operation (Augmentation policy)
- Manually designed augmentation policy: Engineer manually does hand tuning.
- Automatic augmentation policy searching: Uses a search algorithm to discover the optimal augmentation policy (combination) for a given dataset and tasks.
First of all, automatically designed single operation is not designed with an engineer’s intuition or experience. It utilizes an augmentation network (DNN) for augmentation, and the engineer just sets the appropriate objective (objective function or loss function) to train the DNN. The DNN learns to become an augmenting operator by making good augmentations by itself.
Automatic augmentation policy searching means searching for policies that combine augmentation operations. Given a dataset and a task, it automatically explores how to combine existing augmenting operations (rotation, invert, shearing, color jittering, cutout, etc.) for optimal augmentation without a DNN. For research on automatic augmentation policy searching, you can refer to the following papers:
- AutoAugment (CVPR 2019)
- Fast AutoAugment (NeurlPS 2019)
Fast AutoAugment
Data augmentation is an essential technique for improving generalization ability of deep learning models. Recently, AutoAugment has been proposed as an algorithm to automatically search for augmentation policies from a dataset and has significantly enhanced performances on many image recognition tasks. However, its search method requires thousands of GPU hours even for a relatively small dataset. In this paper, we propose an algorithm called Fast AutoAugment that finds effective augmentation policies via a more efficient search strategy based on density matching. In comparison to AutoAugment, the proposed algorithm speeds up the search time by orders of magnitude while achieves comparable performances on image recognition tasks with various models and datasets including CIFAR-10, CIFAR-100, SVHN, and ImageNet.
https://arxiv.org/abs/1905.00397
- Population based augmentation: Efficient learning of augmentation policy schedule (ICML 2019)
Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules
A key challenge in leveraging data augmentation for neural network training is choosing an effective augmentation policy from a large search space of candidate operations. Properly chosen augmentation policies can lead to significant generalization improvements; however, state-of-the-art approaches such as AutoAugment are computationally infeasible to run for the ordinary user. In this paper, we introduce a new data augmentation algorithm, Population Based Augmentation (PBA), which generates nonstationary augmentation policy schedules instead of a fixed augmentation policy. We show that PBA can match the performance of AutoAugment on CIFAR-10, CIFAR-100, and SVHN, with three orders of magnitude less overall compute. On CIFAR-10 we achieve a mean test error of 1.46%, which is a slight improvement upon the current state-of-the-art. The code for PBA is open source and is available at https://github.com/arcelien/pba.
- DADA: Differentiable automatic data augmentation (ECCV 2020)
DADA: Differentiable Automatic Data Augmentation
Data augmentation (DA) techniques aim to increase data variability, and thus train deep networks with better generalisation. The pioneering AutoAugment automated the search for optimal DA policies with reinforcement learning. However, AutoAugment is extremely computationally expensive, limiting its wide applicability. Followup works such as Population Based Augmentation (PBA) and Fast AutoAugment improved efficiency, but their optimization speed remains a bottleneck. In this paper, we propose Differentiable Automatic Data Augmentation (DADA) which dramatically reduces the cost. DADA relaxes the discrete DA policy selection to a differentiable optimization problem via Gumbel-Softmax. In addition, we introduce an unbiased gradient estimator, RELAX, leading to an efficient and effective one-pass optimization strategy to learn an efficient and accurate DA policy. We conduct extensive experiments on CIFAR-10, CIFAR-100, SVHN, and ImageNet datasets. Furthermore, we demonstrate the value of Auto DA in pre-training for downstream detection problems. Results show our DADA is at least one order of magnitude faster than the state-of-the-art while achieving very comparable accuracy. The code is available at https://github.com/VDIGPKU/DADA.
- RandAugment: Practical automated data augmentation with a reduced search space (NeurlPS 2020)
https://papers.nips.cc/paper/2020/hash/d85b63ef0ccb114d0a3bb7b7d808028f-Abstract.html
In this article, we looked into the importance and limitations of data augmentation in DL and introduced automatic data augmentation policy searching out of automatic data augmentation as a methodology for solving such limitations. We believe that the studies introduced here are not just limited to image data, so it’s important to find out how they are applied to other data and consider whether they can be included in the automatic data augmentation methodology.
© SAIGE All Rights Reserved.